Content:
➤ Who is this app for
➤ How to use
➤ Chat
➤ History
➤ Models
➤ Settings
➤ Future features
➤ Current engine implementations
➤ Future Integrations
➤ Additional resources to read
➤ Architecture
➤ Tech stack
Hello!
In my free time, I wrote an application with which you can download and run AI LLM neural networks such as Google Gemma, DeepSeek, Llama, Qwen and many others on your smartphone.

There are quite a lot of AI applications now, but the key difference of this one is that the models do not work in the cloud on servers, but directly on the smartphone from the model file, using the processor and video card of the smartphone.
To run, you do not need the Internet, a paid subscription, it is enough to have a smartphone with 6+ GB of RAM and a more or less modern processor.
The application works with the HuggingFace repository this is the largest repository with millions of OpenSource models, of which thousands are large language models, or LLM.
The application can open the most common model format .gguf using the LLama.cpp engine, as well as the format from Google for the MediaPipe engine – .task and .tflite (versions for MediaPipe are in the Google repository).
For some models, such as Gemma 3n (OpenSource version of Gemini) via the MediaPipe engine, image processing is supported.
At the moment, the application is free, but if I can not find a way to pay for my work on writing it, some functions in it will become paid.
It is the largest repository of millions of OpenSource models, of which thousands are Large Language Models, or LLMs.
The application can open the most common format of models .gguf using the LLama.cpp engine, as well as the Google format for the MediaPipe engine – .task And .tflite (versions for MediaPipe are available in the Google repository).
For some models, such as the Gemma 3n (OpenSource version of Gemini) via the MediaPipe engine, it is supported image processing.
This app is made primarily for AI enthusiasts, also for those who cannot use cloud models like ChatGPT or Gemini due to possible data leakage, also for people who do not have constant access to the Internet.
At the moment the app is free, but if I can’t find a way to pay for my work on writing it, some of the features in it will become paid.
➤ Who is this app for
This app is designed for:
- AI enthusiasts who want to download and try out new models, try out different fine-tuning of models.
- People who for some reason cannot use the internet, for example, they are in an area where there is no internet, or are flying on an airplane.
- People who cannot use cloud models because they are afraid of data leakage, or the company where they work prohibits using cloud models.
➤ How to use
The application has tabs: Chat, History, Models, Settings.
➤ Chat
This tab contains a chat with the currently running model.
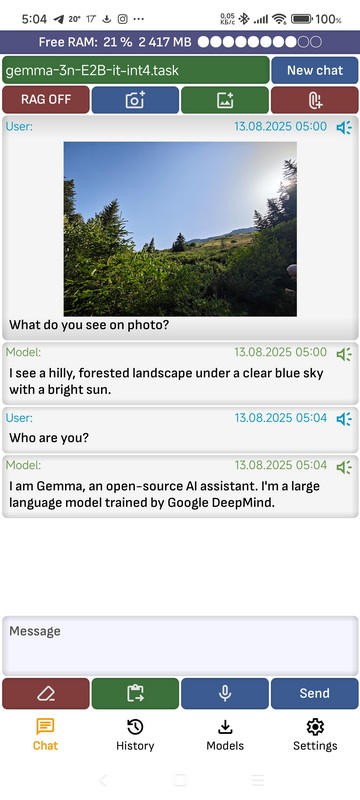
- New chat: Clears the history of the dialogue with the model.
- Share image icon: You can add a picture to the chat. Currently only the MediaPipe engine and the Gemma 3n and Gemma 3 4B 12B 27B models are supported.
- Make photo icon: You can take a photo and send it to the chat. Currently only the MediaPipe engine and the Gemma 3n and Gemma 3 4B 12B 27B models are supported.
- Attach document icon: You can attach a document in pdf, txt, doc, docx format.
As soon as the document is no longer loaded, it will be added to the message context. - RAG ON / OFF: Enable or disable RAG, it is used to add vector database search results to the dialog context.
- Clear text: Current text message is cleared.
- Paste text: Pastes text from the clipboard to the current message input position.
- Voice input: When pressed, voice input is activated. After voice input is complete, if the option “Automatically send text to model after voice recognition is complete” is selected in the application settings, the text is sent to the model, if not selected, you need to send the text by pressing the Send button.
- Send: Send a message to the model. The button text may change depending on the model’s state.
- Microphone symbol on message: Speaks a message. You can adjust the pronunciation speed in the application settings using “Voice speed”. If the “Automatically speak answers after generation” function is activated in the application settings, the message will be spoken automatically by the voice after the model has completed generation.
- Click on the message: A menu will open where you can choose to copy the message to the clipboard, share the message with other applications, or speak the message.
- Top panel: Shows which model is currently being dialogued with. It also shows the amount of free RAM if the “Print free ram on screens” option is enabled.
➤ History
Shows a list of all dialogs with all models.
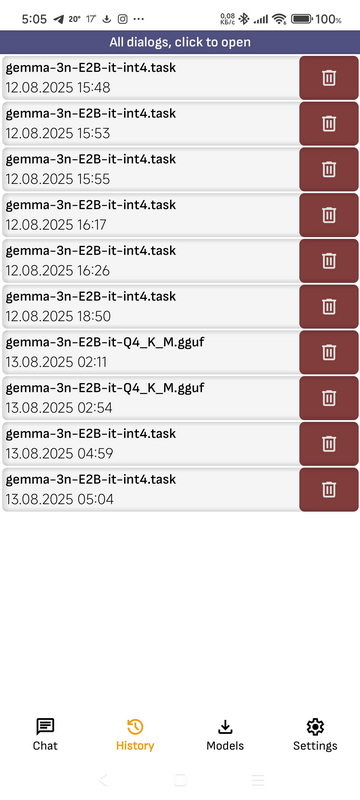
- Press to dialog: Opens a dialog with the model.
- Delete: Deletes the dialogue with the model. All dialogues can be deleted in the application settings, if you click “Clear chat history”
- Continue dialog: You can continue any dialogue. When you continue a dialogue, it will be saved as a new dialogue. When you click on it, a list of all available models will open, with any of them you can continue a previously started dialogue, even if it was with another model. Please note that the context of models is limited. If the dialogue includes a large amount of text, the context of the model may end, in which case part of the dialogue may be lost. You can adjust the size of the context of the model in the application settings. Please note that the size of the context is not the number of characters, but the number of tokens, which usually correspond to a part of a word.
➤ Models
Here you will find all downloaded models, as well as models launched in Ollama and LM Studio on your computer. The model is linked to a file located in the application folder. You can open the folder in some file managers, such as ES Explorer, and add or remove models yourself.
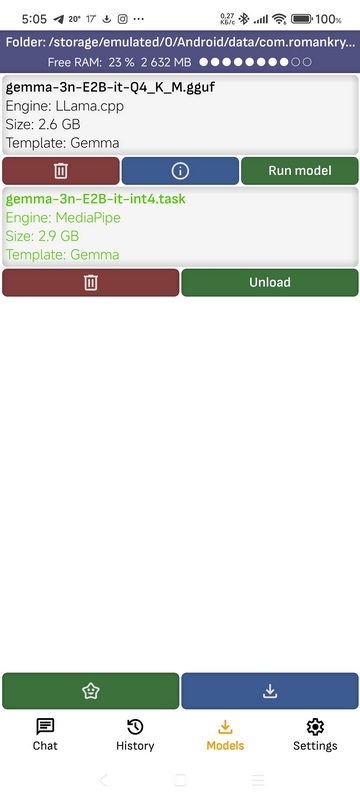
- Run model: Launches the model, while all other models are unloaded. If the model is launched on a computer in a local network, the model is not launched, but a dialog with it is opened, since the launch of the model is controlled by the program in which it is launched.
- Show info: A page with service information for the model opens.
- Click on the model: The model will open in a supported file manager. Please note that not all file managers support opening files, and not all file managers have permission to open another application’s folder.
- Delete: Deletes a model. Deleting models running in Ollama on a computer in the local network is also supported.
- Top panel: Shows the application folder where the models are located. When you click on the folder, you can open it in the file manager, or its path can be copied or shared. It also shows the amount of free RAM if the “Print free ram on screens” option is enabled.
- Download models: Go to the page for downloading models from the HuggingFace repository
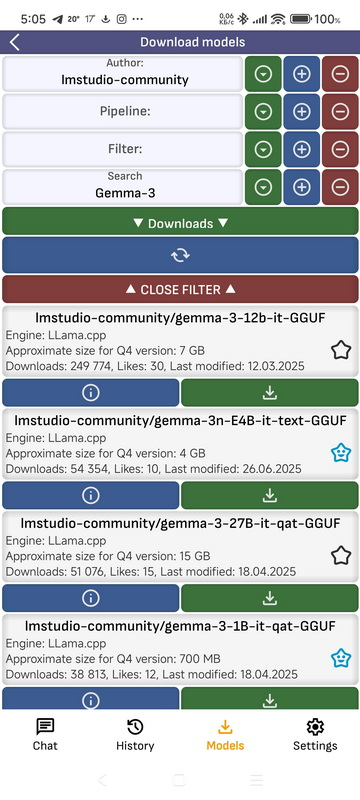
- Author: Filtering the list of models by author. You can enter text and choose from presets.
- Pipeline: Filtering the list of models by pipeline. You can enter text and choose from presets.
- Filter: Filtering the list of models by filter. You can enter text and choose from presets.
- Search: Filtering the list of models by model name. You can enter text and choose from presets.
- Sort parameter: By what parameter to sort the list.
- ▼: Open the list of presets for the corresponding filtering parameter.
- +: Save the parameter entered in the text field to the presets.
- –: Erase the parameter entered in the text field from the presets.
- Refresh: Updates the list.
- Close filter: Hides the filter window
- Open repo on model: Opens the model page on the HuggingFace repository.
- Download: A list with all available models in the repository opens. Models with Q4 quantization suitable for the Arm architecture will be marked in green. If your smartphone has a fast processor and the model is not large, you can try to download and run a model with any quantization. The higher the quantization number, the higher the accuracy of the model. After clicking, the current loading status of the model will be shown at the top of the screen. If you click on it, the loading will stop.
- Bookmarks: Here are the models you have added to your bookmarks
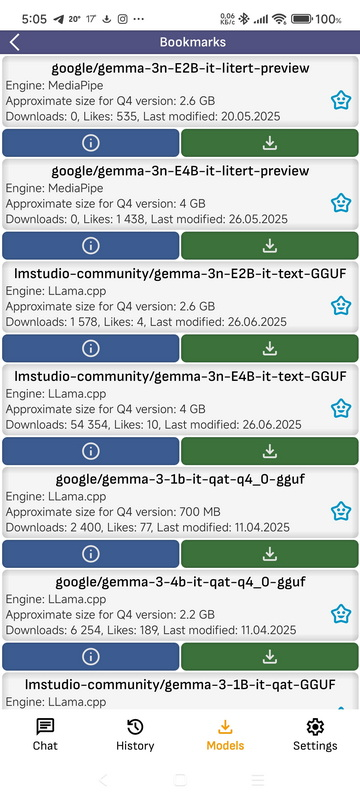
- Author: Filter the list of models by author. You can enter text and select one of the presets.
- Conveyor: Filtering the list of models by pipeline. You can enter text and select one of the presets.
- Filter: Filtering the list of models by filter. You can enter text and select one of the presets.
- Search: Filter the list of models by model name. You can enter text and select one of the presets.
- Sort option: By what parameter to sort the list.
- ▼: Open the list of presets for the corresponding filtering parameter.
- +: Save the parameter entered in the text field to the presets.
- -: Remove the parameter entered in the text field from the presets.
- Update: Refresh the list.
- Close filter: Hide the filter window.
- Open repository by model: Open the model page in the HuggingFace repository.
- Download: Open a list of all available models in the repository. Models with Q4 quantization, suitable for the Arm architecture, will be marked in green. If your smartphone has a fast processor and the model is small, you can try to download and run a model with any quantization. The higher the quantization number, the higher the accuracy of the model. After clicking, the current loading status of the model will be displayed at the top of the screen. If you click on it, the loading will stop.
➤ Settings

- Application Settings

- Select language: Changes the language of the application. If you select System, the language will change depending on the device language. Currently supported languages are English, German, French, Spanish, Polish, Russian, Ukrainian
- View mode: Application theme, dark, light or system.
- Voice settings: Pronunciation settings, here you can choose automatic pronunciation of the message after generation, automatic sending of the message after recognition, pronunciation speed.
- Debug settings: Here you can choose whether to print the amount of available RAM on the screens, and also go to the LLama.cpp engine debug information page
- LLama.cpp engine debug information page: Here you can, after turning on the switch, view the service information that the engine prints to the console during model loading and response generation. Different debug levels are shown in different colors.
- HuggingFace Repository Token: To download some models from the HuggingFace repository, such as models from Google, a token is required. You can enter the token manually. If you have not done this, the application supports authorization using the HuggingFace website. If authorization is required for a model, the application will try to authorize using the website and add the received token, in which case it will be shown in the token field.
- Copy / Paste application settings to clipboard: You can copy all application settings in Json format to the clipboard, paste application settings from the clipboard or send them as a text message. Please note that different versions of the application may have incompatible settings.
- Review application: Rate the app on Google Play. Please note that this is an experimental app, in some cases and with some models it may not work stably.
- Clear chat history: Clear all saved messages.
- Restore default application settings: Removes all application settings. Sometimes when updating the application version, if critical errors related to application settings were found in the previous version, when updating to a more stable version, the previous settings will also be removed.
- Memory settings

- Memory settings: Running LLM models on a smartphone requires a lot of free RAM. On this screen, you can see the current state of available RAM, and also configure notifications or unloading the model if there is not enough memory. The C++ engine code has a function integrated that takes parameters from this screen and stops generation if the memory becomes too low, but in some cases the memory may run out suddenly, in which case the application will close. The size of the model context directly affects how much RAM it consumes. You can configure the context size on the engine settings page. The Memory Configuration page also shows the processor architecture and supported instruction set.
- Prompt settings: On this page you can create, edit, save to presets and delete from presets prompts. Prompt is used for all engines and is added to the first message of the dialog. The default prompt cannot be deleted, also when changing the language the default prompt is reset for the selected language. If you want to use your own prompt, do not save it as the default prompt.
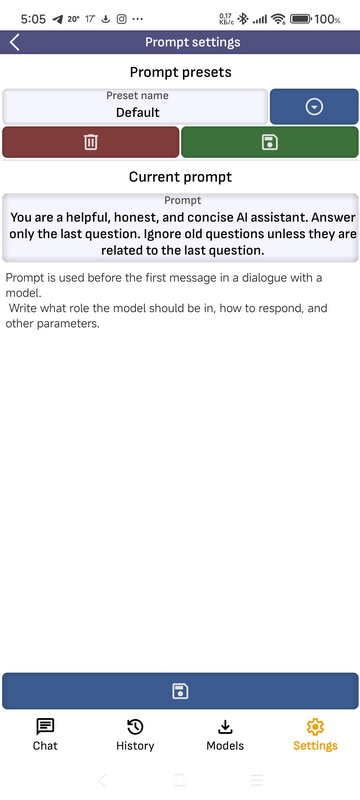
- Template settings: To communicate with different models, the LLama.cpp engine uses different template. Usually, presets are the same for the same model family. On this page, you can update or add presets for different models. If there is currently a model running in the application, opening this page will select the template that corresponds to it.

- Template name: Template are linked to the downloaded model via “Model name key world”. You can write names for several models via if they use the same preset.
- Template for first message: The template for the first message must include a prompt. When sending a message to a model, the prompt_text parameter is replaced with the prompt, and the message_text parameter is replaced with the user’s message.
- Stop generation key world: A keyword that, upon receiving in response from the model, the application will stop generation. This is necessary for some models, during training or modification of which errors were made, as a result of which the model may use incorrect keywords that the engine will not understand and generation will occur endlessly. You can use multiple keywords separated by ,
- Replace key world: Some models may return service keywords in the response, here you can list which keywords will be removed from the response, in the format “keyword” -> “what it can be replaced with”. For example, you can replace the service tag about what the model thinks with your general opinion
- LLama.cpp engine settings: LLama.cpp engine settings. You can save settings to presets. You can read more about the settings and how they affect in the articles on LLM models. Here are some of them:
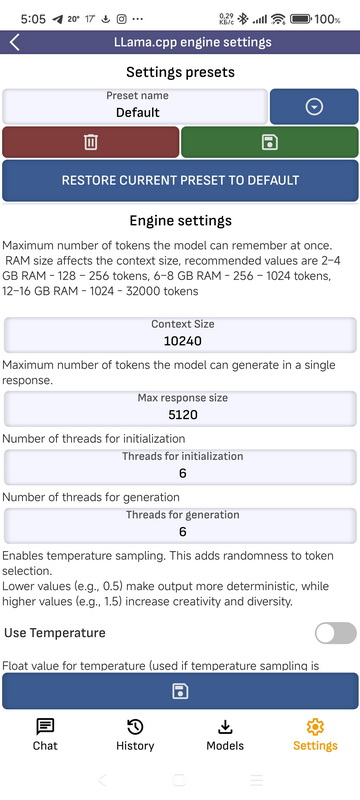
- Context size: Maximum number of tokens the model can “remember” at once. RAM size affects the context size, recommended values are 2–4 GB RAM – 128 – 256 tokens, 6–8 GB RAM – 256 – 1024 tokens, 12–16 GB RAM – 1024 – 32000 tokens.
- Response size: Maximum number of tokens the model can generate.
- Temperature: Float value for temperature (used if temperature sampling is enabled). Controls randomness. 1.0 = neutral, 0.7 = conservative, 1.3 = creative.
- Top-K: Integer value for Top-K. Used if use_top_k is true. Specifies how many top tokens are kept.
- Top-P: Float value for Top-P. Used if use_top_p is true. Represents the cumulative probability threshold (e.g., 0.9).
- Threads: Number of threads used for initialization.
- Threads batch: Number of threads used for generation.
- Samplers: Selecting a sampler that will process the raw values.
- More: You can find more information in my article Neural networks in simple terms
- MediaPipe engine settings: MediaPipe engine settings. The settings repeat some of the settings from LLama.cpp

- LocalHost engine settings:
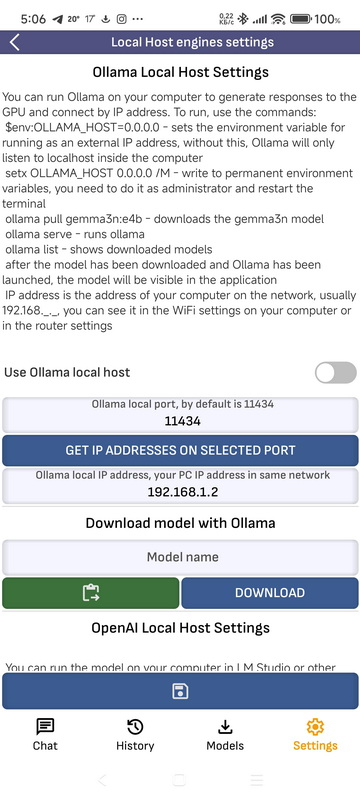
- Ollama LocalHost Settings: You can run Ollama on your computer to generate responses to the GPU and connect by IP address. To run, use the commands: $env:OLLAMA_HOST=”0.0.0.0″ – sets the environment variable for running as an external IP address, without this, Ollama will only listen to localhost inside the computer setx OLLAMA_HOST 0.0.0.0 /M – write to permanent environment variables, you need to do it as administrator and restart the terminal ollama pull gemma3n:e4b – downloads the gemma3n model ollama serve – runs ollama ollama list – shows downloaded models after the model has been downloaded and Ollama has been launched, the model will be visible in the application IP address is the address of your computer on the network, usually 192.168.., you can see it in the WiFi settings on your computer or in the router settings
- OpenAI LocalHost Settings: You can run the model on your computer in LM Studio or other programs compatible with the OpenAI API to generate responses for the GPU and connect by IP address. IP address is the address of your computer on the network, usually 192.168.., you can see it in the WiFi settings on your computer or in the router settings To listen to LM Studio on your computer’s port, select LM Studio – Developer – Settings – Serve on Local Network and run it by setting the Status switch to Running
- RAG settings:

If you added a document to the model dialog and its size does not exceed the limit set on the settings page, it will be added entirely to the model dialog context when generating a response.
If the document limit is higher, it will be split into parts, each part will be vectorized, and when generating a response, a suitable vector will be found and its text will be added to the conversation context. Results count: The number of search results in the vector database and the number of results from the added document that will be added to the context when generating the response. Minimum similarity score: Defines the minimum allowed similarity value between two vectors for them to be considered a match..
Pairs with a similarity below this threshold are ignored in the results..
Typical recommended MinSimilarityScore values:.
0.7–0.8 for strict matches with high relevance..
0.5–0.7 for moderate similarity where partial matches are acceptable..
small then 0.5 only for broad recall or exploratory searches. Add attached documents to the vector database: The document added during a conversation with the model will also be added to the vector database, in this case, with RAG enabled, each time a request is made, a search will be performed in the vector database and the appropriate document will be added to the context of the question. Chunk token size: Maximum number of tokens allowed in a single text chunk before splitting.
If set too high, the embedding model may fail or produce errors because it exceeds the model’s maximum input size. Chunk overlap, only for sentences method: Defines the number of tokens from the end of one chunk that are repeated at the start of the next to preserve context. Split chunks of text larger than this value into pieces: Break text into chunks if it is larger than this number of characters.
Also affects documents added during a dialog, all documents larger than this value are converted into vectors and a search is performed by vectors.
If the document is too large, the LLM model will run out of content and will not be able to generate a response. Chunk max symbols limit: Limit the number of characters in a chunk.
If the Sentences method is used, the length of sentences can be large, and this will lead to the embedding model crash.
- Vector database settings:

You can manually add a document or text to the vector database.
When adding to the database, the document will be split into pieces, and a vector will be generated for each piece.
If RAG is enabled in the dialog box with the model, each time your question is generated, it will be converted into a vector, suitable document fragments will be found in the vector database and added, and their text will be added to the context of your question.
You can also check what documents can be found in the database using the query text, for this you can use a filter.
➤ Future features
- LocalHost Server API: The app will work as a server compatible with OpenAI API and Ollama API
- Function calling: Support for On-Device Function Calling SDK, it is temporarily disabled for now as it does not support some functions required for other functions of the application.
- LiteRT-LM NPU: LiteRT-LM engine will be added, I got access to the documentation and maybe I can add support
➤ Current engine implementations
llama.cpp
- Wikipedia: en.wikipedia.org/wiki/Llama.cpp.
- GitHub: github.com/ggml-org/llama.cpp
- Android: github.com/ggml-org/llama.cpp/tree/master/examples/llama.android
MediaPipe / TensorFlow
- Google Guide: ai.google.dev/edge/mediapipe/solutions/guide .
- GitHub: github.com/google-ai-edge/mediapipe.
- HuggingFace: huggingface.co/litert-community
- Kaggle Model: kaggle.com/models/google/gemma-3/tfLite
- Maven: mvnrepository.com/artifact/com.google.mediapipe
Local Host Engines
- Ollama: Ollama API is supported, you can run Ollama on PC and communicate with the model from the application
- OpenAI API: OpenAI API is supported, you can run LM Studio or any OpenAI API compatible application on your PC and communicate with the model from the application
➤ Future Integrations
LiteRT-LM
Will be added along with support for NPU and .litertlm models once it leaves alpha testing
- About: https://ai.google.dev/edge/litert/next/npu
- GitHub: https://github.com/google-ai-edge/LiteRT-LM
MLC LLM
so far only experimental use, since the models on HuggingFace consist of many files, and their use is not convenient, also the engine is poorly optimized for Android and the models work slower than llama.cpp and MediaPipe, in the future it is planned to repackage some models into a specialized format in one file and upload them to HuggingFace
- Repository: github.com/mlc-ai/mlc-llm
- Deploying the CLI: llm.mlc.ai/docs/deploy/cli.html.
- Android Deployment: llm.mlc.ai/docs/deploy/android.html.
- Compilation of models: llm.mlc.ai/docs/compilation/compile_models.html.
- HuggingFace: huggingface.co/mlc-ai
- Example model: huggingface.co/google/gemma-3-1b-it-qat-q4_0-unquantized
ONNX
so far only experimental use, since models on HuggingFace consist of many files and there is no way to pack them into one file, using the engine is not convenient and it works slowly under Android
- Wikipedia: en.wikipedia.org/wiki/Open_Neural_Network_Exchange
- ONNX Runtime for GenAI (Java): github.com/microsoft/onnxruntime-genai/tree/main/src/java
- API documentation: onnxruntime.ai/docs/genai/api/java.html.
- HuggingFace: huggingface.co/onnx-community
- Maven: mvnrepository.com/artifact/com.microsoft.onnxruntime
PyTorch
I plan to add
- Wikipedia: ru.wikipedia.org/wiki/PyTorch
- Official website: pytorch.org.
- Repository: github.com/pytorch/pytorch
➤ Additional resources to read
- Large language model (Wikipedia)
- List of major language models (Wikipedia)
- Lama (language model) (Wikipedia)
- Language Model Test (Wikipedia)
- Document Evaluation Model (arXiv)
➤ Architecture
- Modular Clean Architecture by Robert C. Martin
https://en.wikipedia.org/wiki/Robert_C._Martin
➤ Tech stack
- Languages: Kotlin, Java, C++
- Build System: Gradle Groovy DSL, CMake