Содержание:
➤ Для кого это приложение?
➤ Как использовать
➤ Чат
➤ История
➤ Модели
➤ Настройки
➤ Будущие возможности
➤ Текущие реализации движка
➤ Будущие инициативы
➤ Дополнительные ресурсы для чтения
➤ Архитектура
➤ Технологический стек
Привет!
В свободное время я написал приложение, с помощью которого можно загружать и отключать нейронные сети AI LLM, такие как Google Джемма, DeepSeek, Лама, Квен и многие другие на вашем смартфоне.

Сейчас существует довольно много приложений ИИ, но ключевое отличие этого в том, что модели работают не в облаке на серверах, а прямо на смартфоне из файловых моделей, с использованием процессора и видеокарты смартфона.
Для работы не нужна интернет, платная подписка, достаточно иметь смартфон с 6+ ГБ оперативной памяти и более современным процессором.
Приложение работает с репозиторием HuggingFace и является основным репозиторием миллионов моделей OpenSource, тысячи из которых являются крупными языковыми моделями или LLM.
Приложение может открыть наиболее распространенный формат модели .gguf с использованием движка LLama.cpp, а также форматы от Google для движка MediaPipe — .task и .tflite (версии для MediaPipe есть в репозиториях Google).
Для некоторых моделей, таких как Gemma 3n (OpenSource-версия Gemini) через движок MediaPipe осуществляет обработку изображений.
На данный момент приложение бесплатное, но если я не найду способа оплатить свою работу по его написанию, некоторые функции для него станут платными.
Это крупнейшая платформа из миллионов моделей с открытым исходным кодом, тысячи из которых являются крупными языковыми моделями (LLM).
Приложение может открывать наиболее распространенные модели моделей. .gguf с использованием движка LLama.cpp, а также формируется Google для движка MediaPipe — .задача и .tflite (версии для MediaPipe доступны в репозиториях Google).
Для некоторых моделей, таких как Gemma 3n (версия Gemini с открытым исходным кодом) через движок MediaPipe, осуществляется обработка изображений .
Это приложение создано в первую очередь для энтузиастов искусственного интеллекта, а также для тех, кто не может использовать облачные модели, такие как ChatGPT или Gemini, из-за возможной утечки данных, а также для людей, не имеющих постоянного доступа к Интернету.
На данный момент приложение бесплатное, но если я не найду способа оплатить свою работу по его написанию, некоторые его функции станут платными.
➤ Для кого это приложение?
Это приложение предназначено для:
- Энтузиасты ИИ, которые хотят скачать и опробовать новые модели, попробовать различные доработки моделей.
- Люди, которые по каким-то причинам не могут пользоваться Интернетом, например, они находятся в районе, где нет интернета, или летают на самолете.
- Люди, которые не могут использовать облачные модели, потому что происходит утечка данных или компания, где они работают, запрещает использовать облачные модели.
➤ Как использовать
Приложение имеет вкладки: Чат, История, Модели, Настройки.
➤ Чат
Эта вкладка содержит чат с текущей запущенной моделью.
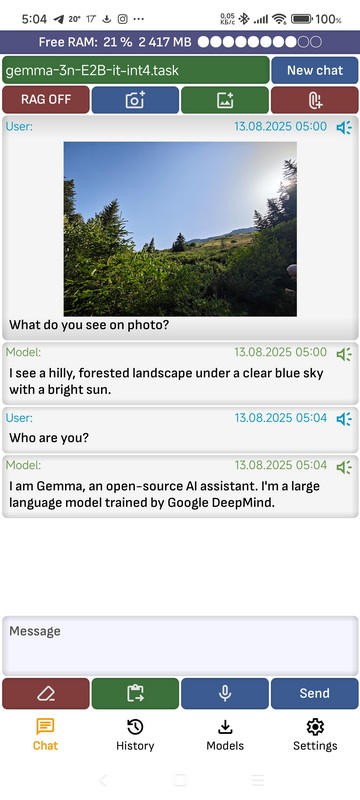
- Новый чат: Очищает историю диалога с моделью.
- Значок «Поделиться изображениям»: Вы можете добавить изображение в чат. В настоящее время применяются только движок MediaPipe и модели Gemma 3n и Gemma 3 4B 12B 27B.
- Сделать значок фото: Вы можете сделать фотографию и отправить ее в чат. В настоящее время применяются только движок MediaPipe и модели Gemma 3n и Gemma 3 4B 12B 27B.
- Значок при подтверждении документа: Вы можете прикрепить документ в форматах pdf, txt, doc, docx.
Как только документ перестанет загружаться, он будет добавлен в контекст сообщения. - ТРЯПКА ВКЛ / ВЫКЛ: включить или отключить RAG, используется для добавления результатов поиска в базу данных векторов в контекстном диалоге.
- Открытый текст: Текущее текстовое сообщение удалено.
- Вставить текст: Вставляет текст из буфера обмена в текущую позицию ввода сообщений.
- Голосовой ввод: При активации голосового ввода. После завершения голосового ввода, если в приложении выбрана опция «Автоматически отправлять текст модели после выполнения запроса», текст продает модели. Если не выбрано, необходимо отправить текст, нажав кнопку «Отредактировать».
- Отправлять: Отправить сообщение модели. Текст кнопки может меняться в зависимости от состояния модели.
- Символ микрофона в сообщении: Производит сообщение. Скорость произношения можно настроить в приложении приложения с помощью параметра «Скорость голоса». Если в приложении приложения включена функция «Автоматически озвучивать ответы после генерации», сообщение будет автоматически воспроизводиться голосом после завершения генерации модели.
- Нажмите на сообщение: Откроется меню, в котором вы можете скопировать сообщение в буфере обмена, поделиться сообщением с другими приложениями или перезапустить сообщение вслух.
- Верхняя панель: показывает, с какой моделью в данный момент ведётся диалог. Также показывает объём свободной оперативной памяти, если включена опция «Вывести объём свободной оперативной памяти на экран».
➤ История
Показывает список всех диалогов со всеми моделями.
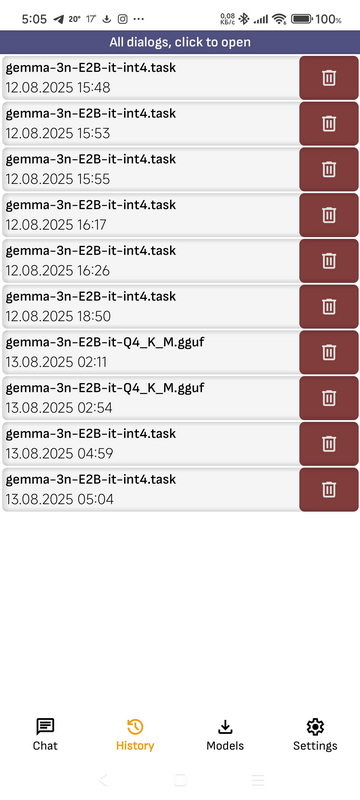
- Нажмите, чтобы открыть диалог: Открывается нижнее окно с моделью.
- Удалить: Удаляет диалог с моделью. Все диалоги можно удалить в меню приложения, нажав «Очистить историю чата».
- Продолжить диалог: Вы можете продолжить любой диалог. При продолжении диалога он будет сохранён как новый диалог. При обращении к нему откроется список всех доступных моделей, с любой из которых вы можете продолжить ранее начатый диалог, даже если это была другая модель. Обратите внимание, что контекст модели ограничен. Если диалог включает в себя текст большого объема, модели контекста могут обостриться, и в этой части диалог может быть потерян. Вы можете настроить размер модели контекста в приложении. Обратите внимание, что размер контекста — это не количество символов, а количество токенов, которые обычно соответствуют части слова.
➤ Модели
Здесь вы найдете все загруженные модели, а также модели, запущенные в Ollama и LM Studio на вашем компьютере. Модель беспокойства с файлом, находящимся в мобильном приложении. Вы можете открыть этот инструмент в некоторых файловых менеджерах, например, в ES Explorer, и самостоятельно добавить или удалить модели.
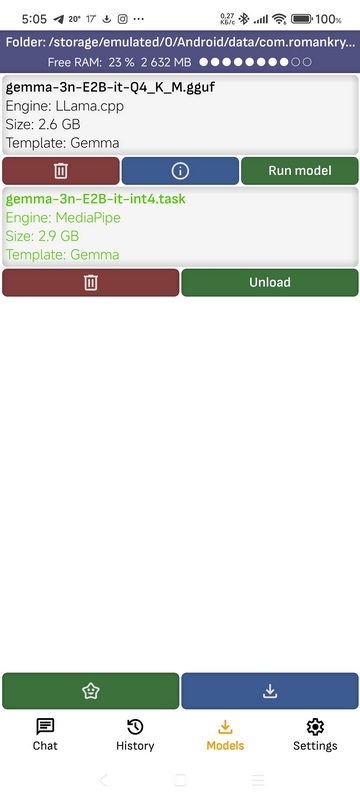
- Запуск модели: Запускается модель, при этом все остальные модели выгружаются. Если модель запущена на компьютере в локальной сети, то она не запускается, но открывает диалог с ней, при запуске модели контролируется программа, в которой она запустилась.
- Показать информацию: Откроется страница с сервисной информацией для моделей.
- Нажмите на модель: Модель откроется в разделе «Файлы управления». Обратите внимание, что не все файловые менеджеры используют открытие файлов, и не все файловые менеджеры имеют разрешение на открытие папок других приложений.
- Удалить: Удаляет модель. Также обеспечивает удаление моделей, запущенных в Ollama на компьютере в локальной сети.
- Верхняя панель: показывает приложение-приложение, в котором управляются модели. Щёлкнув по ссылке, можно открыть её файлы в менеджере, а также скопировать или поделиться путём к ней. Также отображается объём свободной оперативной памяти, если включена опция «Выводить объём свободной оперативной памяти на экран».
- Скачать модели: Перейти на страницу загрузки моделей из репозитория HuggingFace
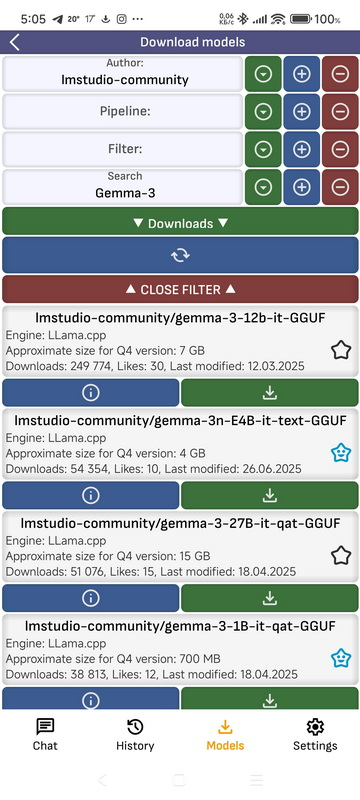
- Автор: Фильтрация списков моделей по автору. Можно ввести текст и выбрать из готовых вариантов.
- Трубопровод: Фильтрация списка моделей конвейера. Можно ввести текст и выбрать предустановки.
- Фильтр: Фильтрация списков моделей по фильтру. Вы можете ввести текст и выбрать предустановленные параметры.
- Поиск: Фильтрация списков моделей по названию. Вы можете ввести текст и выбрать предустановленные параметры.
- Параметр сортировки: По какому параметру сортировать список.
- ▼: Откройте список предустановок для установки фильтра с соответствующим параметром.
- +: сохранить параметр, введенный в текстовое поле, в предустановках.
- —: Удалить параметр, введенный в текстовое поле, из предустановок.
- Обновить: Обновляет список.
- Закрыть фильтр: Закрывает фильтр окна
- Открыть репозиторий по моделям: Открывает страницу модели в репозитории HuggingFace.
- Скачать: Откроется список всех доступных моделей в репозитории. Модели с квантованием Q4, подходящие для конструкции Arm, отмечены зелёным цветом. Если у вашего смартфона быстрый процессор и небольшая модель, вы можете загрузить и запустить модель с любым квантованием. Чем выше количество квантования, тем выше точность моделей. После нажатия в верхней части экрана отобразится текущий статус загрузки модели. Если нажать на него, загрузка прекращается.
- Закладки: Вот модели, которые добавили выи в закладки.
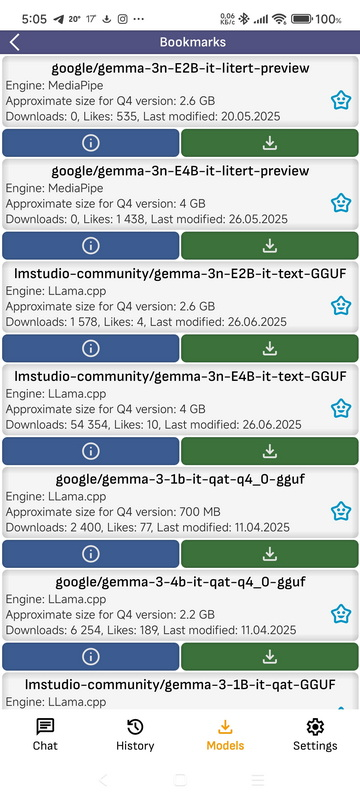
- Автор: Фильтрация списков моделей по автору. Вы можете ввести текст и выбрать один из шаблонов.
- Конвейер: Фильтрация списка моделей конвейера. Вы можете ввести текст и выбрать один из шаблонов.
- Фильтр: Фильтрация списков моделей по фильтру. Вы можете ввести текст и выбрать один из шаблонов.
- Поиск: Фильтруйте список моделей по названию. Вы можете ввести текст и выбрать один из шаблонов.
- Вариант сортировки: По какому параметру сортировать список.
- ▼: Откройте список предустановок для настройки фильтра с соответствующим параметром.
- +: сохранить параметр, введенный в текстовое поле, в предустановках.
- -: Удалить параметр, введенный в текстовое поле, из предустановок.
- Обновить: Обновите список.
- Закрыть фильтр: Закрыть фильтр окна.
- Открыть репозиторий по моделям: Откройте страницу моделей в репозиториях HuggingFace.
- Скачать: Откройте список всех доступных моделей в репозитории. Модели с квантованием Q4, подходящие для конструкции Arm, отмечены зелёным цветом. Если у вашего смартфона быстрый процессор и небольшая модель, вы можете загрузить и запустить модель с любым квантованием. Чем выше число квантований, тем выше точность моделей. После нажатия в верхней части экрана отобразится текущий статус загрузки модели. Если нажать на него, загрузка прекращается.
➤ Настройки

- Настройки приложения

- Выберите язык: Изменяет язык приложения. Если выбрать «Система», язык будет меняться в зависимости от языка устройства. В настоящее время применяются следующие языки: английский, немецкий, французский, испанский, польский, русский, украинский.
- Режим просмотра: Тема приложения, темная, светлая или системная.
- Настройки голосов: Настройки произношения, здесь можно выбрать цену произнесения сообщений после генерации, автоматическую отправку сообщений после поиска, скорость произношения.
- Настройки отладки: Здесь вы можете выбрать, следует вывести на экран объем доступной оперативной памяти, а также перейти на страницу отладочной информации движка LLama.cpp.
- Страница отладочной информации движка LLama.cpp: Здесь, после включения переключателя, можно просмотреть служебную информацию, которую движок выводит на консоль во время загрузки модели и формирования ответа. Различные уровни отладки отдельных цветов.
- Токен репозитория HuggingFace: для некоторых загрузок моделей из репозитория HuggingFace, например, моделей Google, требуется токен. Вы можете ввести токен вручную. Если вы этого не сделали, приложение поддерживает авторизацию через сайт HuggingFace. Если для модели требуется авторизация, попробуйте авторизоваться через сайт и добавить полученный токен. В этом случае он будет подключен в поле токена.
- Копировать/вставить настройки приложения в буфер обмена: Вы можете скопировать все настройки приложений в формате JSON в буфер обмена, вставить их из буфера обмена или отправить SMS-сообщение. Обратите внимание, что настройки разных версий приложений могут быть несовместимы.
- Рассмотрение заявок: Оцените приложение в Google Play. Обратите внимание, что это экспериментальное приложение, и в некоторых случаях и на некоторых моделях оно может работать в автономном режиме.
- Очистить историю чата: Очистить все сохраненные сообщения.
- Восстановить настройки приложения по умолчанию: Удаляет все настройки приложений. Иногда при обновлении версии приложения, если в предыдущей версии были обнаружены серьезные ошибки, связанные с настройками приложения, при обновлении до более стабильной версии настройки также будут удалены.
- Настройки памяти

- Настройки памяти: Запуск моделей LLM на смартфоне требует большого объема свободной оперативной памяти. На этом экране можно увидеть состояние доступа к оперативной памяти, а также настроить уведомления или выгрузку модели при ее недостатке. В коде движка C++ встроена функция, которая принимает параметры с этого экрана и останавливает генерацию при недостаточном объеме памяти. Однако в некоторых случаях память может внезапно прерваться, и приложение закроется. Размер контекстной модели напрямую влияет на объем потребляемой оперативной памяти. Размер контекста можно настроить на странице настроек движка. На странице конфигурации памяти также отображаются архитектура процессора и соответствующий набор инструкций.
- Настройки подсказок: На этой странице вы можете создавать, сохранять, сохранять в предустановках и удалять из предустановок подсказки. Подсказка используется для всех движков и добавлена в первое сообщение диалога. Подсказка по умолчанию удалить нельзя, также при смене языка подсказка по умолчанию сбрасывается на двуязычный язык. Если вы хотите использовать собственную подсказку, не сохраняйте ее как подсказку по умолчанию.
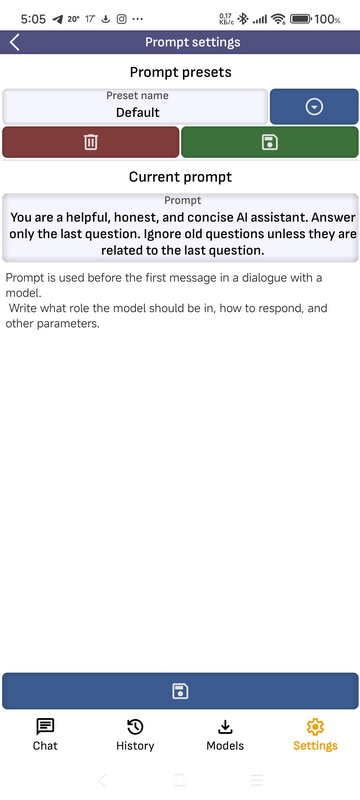
- Настройки шаблона: Для взаимодействия с различными моделями движений LLama.cpp использует различные шаблоны. Обычно предустановки одинаковы для одной модели корпуса. На этой странице вы можете обновить или добавить предустановки для разных моделей. Если в приложении активирована модель, при открытии этой страницы будет выбран соответствующий шаблон.

- Имя шаблона: Шаблоны с загруженной моделью через «Ключ имени модели». Вы можете использовать имена для нескольких моделей, используя один и тот же шаблон.
- Шаблон для первого сообщения: Шаблон первого сообщения должен включать подсказку. При отправке сообщения модели параметр Prompt_text заменяется подсказкой, а параметр message_text — сообщением пользователя.
- Остановить генерацию ключа мира: ключевое слово, при получении которого от модели приложение остановить генерацию. Это необходимо для некоторых моделей, при обучении или модификации были допущены ошибки, в результате чего модель может не использовать корректированные ключевые слова, которые движок не распознает, и генерация которых будет происходить бесконечно. Вы можете использовать несколько ключевых слов, разделенных символами.
- Заменить ключевой мир: модели могут вернуть служебные слова в ответ. Здесь вы можете перечислить ключевые слова, которые будут удалены из ответа, в формате «ключевое слово» -> «чем его можно заменить». Например, вы можете заменить служебный тег о том, что модель головы соответствует вашему общему мнению.
- Настройки движка LLama.cpp Настройки движка LLama.cpp. Вы можете сохранить настройки в виде пресетов. Подробнее об устройствах и их влиянии можно прочитать в статьях о моделях LLM. Вот из некоторых из них:
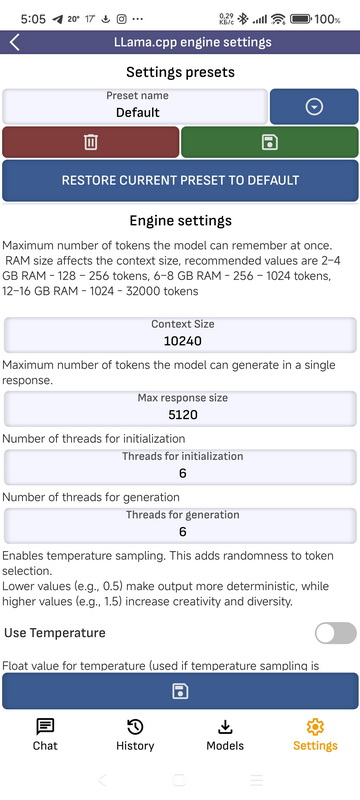
- Размер контекста: Максимальное количество токенов, которую модель может «запомнить» одновременно. Объём ОЗУ влияет на размер контекста, рекомендуемые значения: 2–4 ГБ ОЗУ — 128–256 токенов, 6–8 ГБ ОЗУ — 256–1024 токенов, 12–16 ГБ ОЗУ — 1024–32000 токенов.
- Размер ответа: Максимальное количество токенов, которое может сгенерировать модель.
- Температура: Плавающее значение температуры (используется, если включен выбор температуры). Управляет случайностью. 1,0 = нейтрально, 0,7 = наблюдательно, 1,3 = творчески.
- Топ-К: Целочисленное значение для Топ-К. Используется, если use_top_k имеет значение true. Указывает количество хранящихся на верхних поверхностях жетонов.
- Топ-П: Плавающее значение для Топ-П. Используется, если use_top_p равно true. имеет пороговое значение кумулятивной вероятности (например, 0,9).
- Темы: Количество потоков, использованных для соединения.
- Пакет потоков: Количество потоков, использованных для генерации.
- Сэмплеры: Выбор сэмплера, который будет обрабатывать необработанные значения.
- Более: Более подробную информацию вы можете найти в моей статье. Нейронные сети простые слова
- Настройки движка MediaPipe: Настройки движка MediaPipe. Эти настройки частично повторяют настройки из LLama.cpp.

- Настройки движка LocalHost :
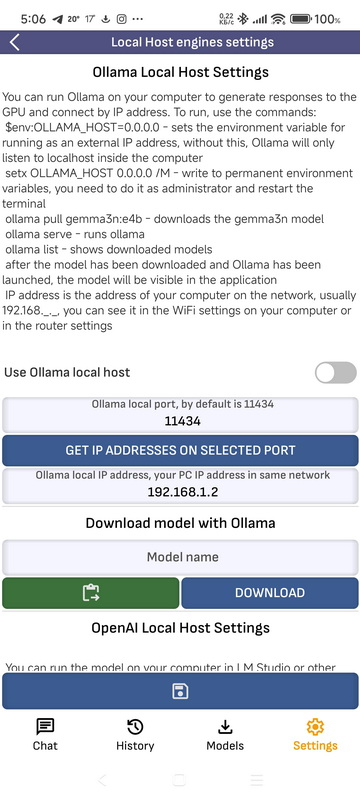
- Настройки локального хоста Ollama Вы можете запустить Ollama на компьютере, чтобы ограничить ответы для графического процессора и подключиться по IP-адресу. Для запуска команды: $env:OLLAMA_HOST="0.0.0.0" — устанавливает переменное окружение для работы с внешним IP-адресом, без этого Ollama будет слушать только локальный хост внутри компьютера setx OLLAMA_HOST 0.0.0.0 /M — запись в постоянные переменные окружения, это нужно сделать от имени администратора и перезапустить терминал оллама тянуть gemma3n:e4b — загружает модель gemma3n подача олллама — бежит оллама список оллама — показывает загруженные модели после загрузки модели и запуска Ollama, модель будет видна в приложении IP-адрес — адрес вашего компьютера в сети, обычно 192.168.1.1. ., вы можете увидеть это в системе Wi-Fi на вашем компьютере или в маршрутизаторе
- Настройки OpenAI LocalHost: Вы можете активировать модель на своем компьютере в LM Studio или других программах, совместимых с API OpenAI, чтобы получить ответы для графического процессора и подключиться по IP-адресу. IP-адрес — это адрес вашего компьютера в сети, обычно 192.168.1.1. ., вы можете увидеть его через Wi-Fi на своем компьютере или через маршрутизатор. Для прослушивания LM Studio на порту вашего компьютера выберите LM Studio — Разработчик — Настройки — Обслуживать в локальной сети и заблокируйте его, установив переключатель «Состояние работы».
- Настройки RAG :

Если вы добавили документ в соседнее окно модели и его размер не ограничивает лимит страницы, установленный в настройках, то при повороте ответа он будет добавлен в контекст соседнего окна модели.
Если ограничить документ выше, он будет разделен на части, каждая часть будет векторизована, а при выборе значения будет найден соответствующий вектор, и его текст будет добавлен в разделы контекста. Результаты рассматриваются: количество результатов поиска в векторной базе данных и количество результатов из добавленного документа, которые будут добавлены в контекст при повороте ответа. Минимальная точность сходства: определяет минимально допустимое значение сходства между двумя векторами, чтобы они считались совпадениями.
Пары со сходством ниже этого порога в зоне препятствий отключаются.
Типичные рекомендуемые значения Минимальный показатель сходства:.
0,7–0,8 для строгих соответствий с высокой релевантностью.
0,5–0,7 для умеренного сходства, где допускаются частичные совпадения.
менее 0,5 только для широких примечаний или исследовательского поиска. Добавить включенные документы в векторные ресурсы данных: Документ, добавленный во время разговора с моделью, а также будет добавлен в векторные ресурсы данных, в этом случае, при включенном RAG, каждый раз при выполнении запроса будет выполняться поиск в векторной базе данных, и соответствующий документ будет добавлен в запрос контекста. Размер фрагмента токена: Максимальное количество токенов, разрешенное в одном текстовом фрагменте перед разделением.
Если значение слишком велико, модель встраивания может дать сбой или выдать ошибку, поскольку превысит максимальный размер входных данных модели. Перекрытие фрагментов, только для метода, предлагает: Определить количество токенов с конца одного фрагмента, которые повторяются в начале следующего, для сохранения контекста. Разделить фрагменты текста, превышающие это значение, на части: Разбить текст на части, если его длина увеличит указанное количество символов.
Также влияет на документы, добавленные во время диалога, все документы большего значения преобразуются в текст и выполняют поиск по векторам.
Если документ слишком большой, модель LLM исчерпает ограничения и не сможет сгенерировать ответ. Максимальное количество символов в блоке: Ограничьте количество символов в блоке.
При использовании метода Sentences длина предложения может быть большой, и это приведет к сбою модели встраивания.
- Настройки векторной базы данных :

Вы можете вручную добавить документ или текст в векторные ресурсы данных.
При добавлении в базу данных документ будет делиться на части, и для каждой части будет сформирован вектор.
Если в соседнем окне с моделью включен RAG, то каждый раз при формировании вашего вопроса он будет преобразован в вектор, в базе векторов будут найдены и добавлены под фрагменты документа, а их текст будет добавлен в контекст вашего вопроса.
Вы также можете проверить, какие документы можно найти в базе данных по тексту запроса, для этого можно воспользоваться фильтром.
➤ Будущие возможности
- API-сервер LocalHost: приложение будет работать как сервер, совместимое с API OpenAI и API Ollama.
- Вызов функции: Поддержка SDK для вызова функций на устройстве, на данный момент он временно отключен, так как не поддерживает некоторые функции, необходимые для других функций приложения.
- LiteRT-LM NPU: LiteRT-LM Движок будет добавлен, я получил доступ к документации и, возможно, смогу добавить поддержку
➤ Текущие реализации движка
llama.cpp
- Википедия: en.wikipedia.org/wiki/Llama.cpp.
- GitHub: github.com/ggml-org/llama.cpp
- Андроид: github.com/ggml-org/llama.cpp/tree/master/examples/llama.android
MediaPipe / TensorFlow
- Руководство Google: ai.google.dev/edge/mediapipe/solutions/guide .
- GitHub: github.com/google-ai-edge/mediapipe.
- HuggingFace: huggingface.co/litert-community
- Модель Kaggle: kaggle.com/models/google/gemma-3/tfLite
- Мейвен: mvnrepository.com/artifact/com.google.mediapipe
Локальные хост-движки
- Оллама: Поддерживается API Ollama, вы можете запустить Ollama на ПК и взаимодействовать с моделью из приложения.
- API OpenAI: поддерживает API OpenAI, вы можете запустить LM Studio или любое приложение, совместимое с API OpenAI, на своем ПК и работать с моделированием из приложения.
➤ Будущие инициативы
LiteRT-LM
После завершения альфа-тестирования будет добавлена поддержка моделей NPU и .litertlm.
MLC LLM
пока только экспериментальное использование, так как модели на HuggingFace основаны на доступных файлах, и мне пользоваться неудобно, а также движок плохо сохраняется под Android, и модели работают медленнее, чем llama.cpp и MediaPipe, в дальнейшем планируется перепаковать некоторые модели в специализированном формате в один файл и загрузить на HuggingFace
- Репозиторий: github.com/mlc-ai/mlc-llm
- Развертывание CLI: llm.mlc.ai/docs/deploy/cli.html.
- Развертывание Android: llm.mlc.ai/docs/deploy/android.html.
- Подборка моделей: llm.mlc.ai/docs/compilation/compile_models.html.
- HuggingFace: huggingface.co/mlc-ai
- Пример модели: huggingface.co/google/gemma-3-1b-it-qat-q4_0-unquantized
ONNX
пока только экспериментальное использование, так как модели на HuggingFace основаны на распространенных файлах и нет возможности упаковать их в один файл, пользоваться движком неудобно и он медленно работает под Android
- Википедия: en.wikipedia.org/wiki/Open_Neural_Network_Exchange
- Среда выполнения ONNX для GenAI (Java): github.com/microsoft/onnxruntime-genai/tree/main/src/java
- API-документация: onnxruntime.ai/docs/genai/api/java.html.
- HuggingFace: huggingface.co/onnx-community
- Мейвен: mvnrepository.com/artifact/com.microsoft.onnxruntime
PyTorch
Я планирую добавить
- Википедия: ru.wikipedia.org/wiki/PyTorch
- Официальный сайт: pytorch.org.
- Репозиторий: github.com/pytorch/pytorch
➤ Дополнительные ресурсы для чтения
- Большая языковая модель (Википедия)
- Список основных языковых моделей (Википедия)
- Лама (языковая модель) (Википедия)
- Тест языковой модели (Википедия)
- Модель оценки документов (arXiv)
➤ Архитектура
- Модульная чистая архитектура Роберта К. Мартина
https://en.wikipedia.org/wiki/Роберт_С._Мартин
➤ Технологический стек
- Языки: Kotlin, Java, C++
- Система сборки: Gradle Groovy DSL, CMake.